
Why DeepSeek Stands Out: Three Key Factors Behind Its Success
The Chinese AI model’s innovative design enables it to outperform major competitors at significantly lower costs.

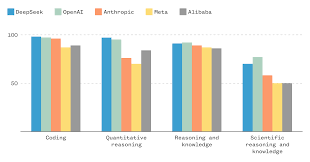
DeepSeek, a once-little-known Chinese artificial intelligence company, has recently captured the tech world’s attention with its impressive lineup of large language models. Since launching its most recent model, R1, on January 20, DeepSeek has disrupted the AI landscape by surpassing many of the world’s leading AI developers, including OpenAI, with its breakthrough technology.
R1, DeepSeek's flagship model, quickly made waves by becoming the top-ranking AI assistant on the Apple App Store, pushing OpenAI's ChatGPT to second place. The model’s rapid success, paired with its performance across various benchmarks, has left Silicon Valley stunned, especially as DeepSeek claims it developed R1 at a fraction of the cost of U.S. models.
This unexpected rise has sparked a reevaluation within the AI industry, suggesting that improving AI models may not require unlimited funding and resources. Instead, it’s now possible to build highly efficient models that balance cost, energy consumption, and performance. DeepSeek’s approach challenges the industry’s assumptions about AI development and shows that innovation can thrive with fewer resources.
Here are the three key features that set DeepSeek apart from other AI models:
1. Size and Efficiency: The "Mixture-of-Experts" System
Despite having fewer resources and a smaller team than its U.S. counterparts, DeepSeek has developed a large and powerful model that runs more efficiently. The company’s use of a "mixture-of-experts" system divides the model into smaller, specialized submodels, or “experts,” each tailored to handle specific tasks or types of data. Unlike traditional models that activate the entire system for every input, DeepSeek activates only the relevant experts for the task at hand, allowing for faster and more efficient processing.
For example, while DeepSeek’s V3 model contains 671 billion parameters, it only utilizes 37 billion at a time, as reported by the company. This enables the model to function with fewer resources without sacrificing performance. The company’s dynamic load-balancing strategy ensures that no single expert is overburdened, further enhancing the model’s efficiency.
Additionally, DeepSeek employs inference-time compute scaling, adjusting the model’s computational effort based on the complexity of the task. Simple tasks require minimal resources, while more complex queries use the full power of the system. This flexibility optimizes the model’s performance and efficiency.
2. Lower Training Costs: Innovation Through Necessity
DeepSeek’s innovative design allows it to train models more cheaply and quickly than its competitors. While major U.S. tech companies spend billions annually on AI, DeepSeek claims that its V3 model, the foundation for R1, cost less than $6 million and took only two months to develop.
One key factor in DeepSeek’s low training costs is its mixed precision framework, which combines 32-bit floating point numbers (FP32) for key operations with 8-bit numbers (FP8) for the majority of calculations. This approach reduces memory usage and processing time, allowing DeepSeek to save both money and resources.
The company’s limited access to advanced Nvidia chips, due to U.S. export restrictions, further drove innovation. By using the less powerful Nvidia H800 chips instead of the H100s, DeepSeek was forced to find more efficient ways to build its models. This has resulted in a design that demonstrates how AI developers could do more with less.
3. Strong Performance: Competing with the Best
Despite operating with fewer resources, DeepSeek’s models consistently perform on par with the best in the industry. In independent benchmarks, R1 has demonstrated comparable performance to OpenAI’s o1 model, and it has outperformed other top models like Google’s Gemini 2.0 Flash, Anthropic’s Claude 3.5 Sonnet, Meta’s Llama 3.3-70B, and OpenAI’s GPT-4o.
One of R1’s standout features is its ability to explain its reasoning through chain-of-thought analysis. This approach allows the model to break down complex tasks into smaller, manageable steps, mimicking human thinking and enabling users to follow the model’s thought process. R1’s transparency sets it apart from many other models, making it easier for users to understand how the AI reaches its conclusions.
DeepSeek’s previous model, V3, had already outperformed several major AI models, including GPT-4o, Llama 3.3-70B, and China’s own Qwen2.5-72B. The company’s latest model, Janus-Pro-7B, has even surpassed OpenAI’s DALL-E and Stable Diffusion’s 3 Medium in various benchmarks, solidifying DeepSeek’s position as a rising powerhouse in the AI field.
Conclusion
DeepSeek’s innovative approach to AI development has proven that efficiency and performance can go hand in hand, even with limited resources. By leveraging creative solutions like the mixture-of-experts system and mixed precision training, DeepSeek is not only challenging industry norms but also pushing the boundaries of what AI can achieve at a fraction of the cost. With R1 and other models gaining traction, DeepSeek is poised to continue making waves in the AI industry, forcing both developers and investors to rethink the future of artificial intelligence.